

Finally, it’s here, with XenApp and XenDesktop version 7.12 Citrix has re-introduced the Local Host Cache functionality. A long awaited feature by many Citrix admins globally. Though many of us are familiar with the LHC feature within 6.5, LHC as part of the FlexCast Management Architecture, which is basically what we are talking about here, is architected differently, or built from the ground up even. This has resulted in a more robust solution, immune to corruption (at least that’s the general idea) also needing less maintenance. Let’s have a look and see what it is about.
Go here to find out what else is new with XenApp/XenDesktop version 7.12
Introduction
As you probably know, the Local Host Cache ensures that connection Site-wide brokering operations will be able to continue (new and existing connections/sessions) even when the connection between your Delivery Controller (s) and the Central Site Database is down or fails altogether. The same applies to the Citrix Cloud (CC) by the way. If, for example your WAN link, which connects you to the CC control plain fails or goes offline for whatever reason, the LHC will ensure that new and existing connections/sessions will continue to be brokered/maintained. Even when your CC, or on-premises Database becomes unreachable, or goes offline for other reasons the LHC will have your back.
Remember that with CC the so-called cloud-connector basically replaces your on-premises Delivery Controller. This is why all the specific LHC services and/or components on your Delivery Controller (s) can be found on your Cloud Connector machines as well.
Before we have a closer look, you should know that with the re-introduction of the LHC Citrix will advise all of her customers to make use of LHC over Connection Leasing (CL) as it is considered far more superior – of course they will have to be on XenApp/XenDesktop version 7.12 to be able to do so. I am not sure what the word is on CL going forward, if it will be deprecated, when etc.? I’m sure we’ll find out soon enough.
So how does it work? Show / tell me!
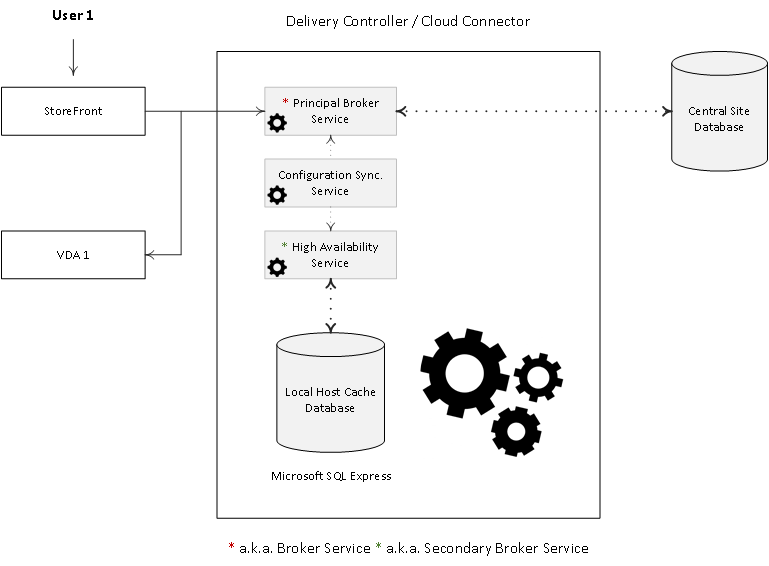
One of the main LHC components is the Broker Service, which as you probably know also functions as the XML Service and the STA, or Secure Ticket Authority in full. When LHC is involved it is also referred to as the Principal Broker Service.
The (Principal) Broker Service will accept connection requests from StoreFront and it communicates with the Central Site Database just like before — brokering connections, taking care of load balancing and so on.
Next to the (Principal) Broker Service we have two new FMA services: the Configuration Synchroniser Service (CSS) and the High Availability Service, which is also referred to as the Secondary Broker Service (yes, both reside on the same Delivery Controller / Cloud Connector).
See the image below for a graphical overview on all this.
Every two minutes the (Principal) Broker Service will be checked for configuration changes. If a configuration change has been detected it will be copied over, or synchronised to the High Availability Service/Secondary Broker Service.
FMA fact: The above mentioned configuration changes include but are not limited to published icons, changes to Delivery Groups and Catalogs, certain Citrix policies and so on. It will not include information about who is connected to which server (Load Balancing), using what application (s) etc. which would fall under the current state of the Site/Farm.
All (synchronised) data is stored in a Microsoft SQL Server Express (LocalDB) database, which resides on the same Delivery Controller as well. In fact, each time new information is copied over, the database will be re-created entirely. This way the CSS can, and will ensure that all configuration data stored in the Central Site Database will match that of the data stored in the local SQL Express database keeping the LHC current.
FMA fact: The local SQL Express database has been part of the XenApp/XenDesktop installation as of version 7.9. It is installed automatically when you install a new controller or upgrade a controller prior to version 7.9.
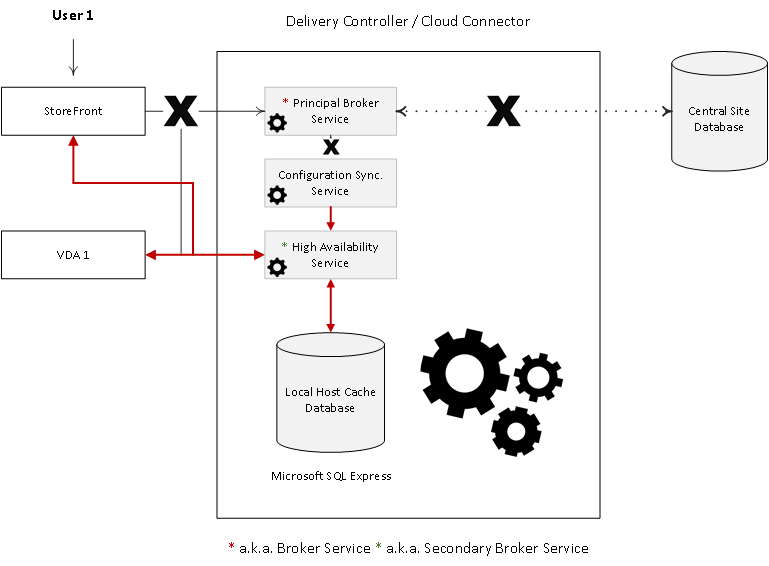
When an outage occurs, the (Principal) Broker Service will no longer be able to communicate with the Central Site Database, as a result it will stop listening for any incoming StoreFront and/or VDA information. It will instruct the High Availability Service/Secondary Broker Service to start listening for incoming connection requests and handle them accordingly.
See the image below for a graphical overview on all this.
As soon as a VDA communicates with the High Availability Service/Secondary Broker Service a VDA re-registration will be triggered. This way the High Availability Service/Secondary Broker Service will receive the most current session information related to that specific VDA (who is connected to which machine, for example). In the meantime, while the High Availability Service/Secondary Broker Service is handling new and existing connections/sessions, the (Principal) Broker Service will continue to monitor the connection to the Central Site Database.
As soon as it notices that the connection to the Central Site Database has been restored it will instruct the High Availability Service/Secondary Broker Service to stop listening for, and handle new and existing connections/sessions. From this point on it will resume brokering operations as before, basically repeating the abovementioned steps of VDA registration to get up to speed with the latest connection/session information.
Finally, the High Availability Service/Secondary Broker Service will remove any remaining VDA registrations and will again continue to update the local SQL Express database (together with the help of the CSS) with any configuration changes from that point on, as highlighted before.
FMA fact: From the E-Docs – In the unlikely event that an outage begins during a synchronization, the current import is discarded and the last known configuration is used.
Modular
To me this again is an excellent example of the FMA’s modularity and flexibility. While all this still takes hard work and dedication from multiple product teams within Citrix, by altering/recoding a couple of existing services (instead of the whole ‘package’ when compared to 6.5) and adding in a few new ones, they were able to completely re-built the LHC from the ground up, and for the better I’d might add.
Zones and multiple controllers
The Configuration Synchronizer Service will provide the High Availability Service/Secondary Broker Service with information on all other controllers within your Site (Primary Zone), this will also include any additional Zones you might have configured. This way each High Availability Service/Secondary Broker Service will know about all of the other available High Availability Service/Secondary Broker Services within your (entire) Site.
Communication between the various High Availability Services/Secondary Broker Services takes place over a separate channel based on a alphabetical list containing the FQDN’s of the machines they (the services) currently run. This information is used to elect which High Availability Service/Secondary Broker Service (read: Delivery Controller) will take over within that specific Zone when the LHC becomes active because of a DB failure or another outage of some sort. Hmm… sounds familiar, right?
FMA fact: We now have LHC for XenDesktop as well. However, do note that the Local Host Cache is supported for server-hosted applications and desktops, and static desktops; it is not supported for pooled VDI based desktops. In other words, resources need to be assigned.
What else?
There is some stuff that you can’t do when the LHC kicks in, like using Studio, for example, or making configuration changes using PowerShell to name another. Have a look at the accompanying LHC E-Docs pages for some more detailed information.
There it will also tell you that the local SQL Express database / the LocalDB Service can use up to 1.2 GB’s of RAM and that the High Availability Service can use up to 1 GB of RAM if the LHC stays active for a longer period of time. In short, you will have to account for some additional memory on top of the usual requirements when it comes to sizing your delivery Controllers.
As for storage, when the LHC is active and VDA’s start re-registering the DB will grow in size. Citrix testing has shown that with a logon rate 10 logons per second the database will grow around one MB every 2-3 minutes. As soon as normal operations resume the local database will be re-created also reclaiming the earlier used space. It goes without saying that your Delivery Controllers will need to have sufficient (free) disk space to cope with this.
Since all connections/sessions will be handled by a single Delivery Controller (including all VDA re-registrations) when the LHC becomes active, the load on that particular machine will probably be higher than usual when, for example, connections/sessions are load balanced among all available Delivery Controllers within the Site/Zone. This will result in a higher than average CPU usage, something to keep in mind as well.
Don’t forget that in theory every Delivery Controller can be elected as the main High Availability Service/Secondary Broker Service, also see the ‘Zones and multiple collectors’ section a few paragraphs up.
5000 VDA’s
This version of the LHC has been tested and validated to successfully manage 5000 VDA’s. This also affects the default enablement of the LHC in combination with the current Connection Leasing configuration when doing an upgrade or performing a new installation.
For example, if you plan on upgrading and your Site has more than 5000 VDA’s the Local Host Cache will be and stay disabled, regardless of the Connection Leasing configuration. If CL is enabled before the upgrade it will stay enabled, if it’s disabled it will stay disabled.
If you have less than 5000 VDA’s, it will depend. When CL is disabled before an upgrade LHC will be enabled and CL will stay disabled. When CL is enabled before an upgrade LHC will be disabled and CL will stay enabled.
It will always be one or the other, never both features, CL and LHC at the same time.
Turning it on and off
Using PowerShell, you have the ability to enable or disable the LHC functionality.
To enable LHC:
Set-BrokerSite -LocalHostCacheEnabled $true -ConnectionLeasingEnabled $false
As you can probably see in the above command, this enables LHC and disbales the CL functionality at the same time.
The same thing happens when the LHC is disabled, see below:
Set-BrokerSite -LocalHostCacheEnabled $false -ConnectionLeasingEnabled $true
Using the Get-BrokerSite cmdlet you will be able to check the current state of the LHC.
CDF Control
When it comes to troubleshooting you have a few options, for one you can start by checking the event logs (a couple of specific events might be generated, see E-Docs), after enablement the CSS can produce a trace report (you can force it to) and finally the Broker Service configuration can be exported for debugging purposes.
But that’s not all. CDF Control can also be used to potentially identify any issues that you might be having.
CDF Control can be used as a stand-alone application (it’s just an executable, nothing more) or as part of Citrix Scout, which will be installed on your Delivery Controllers by default.
CDF tracing works by reading so-called modules, which are built into the various Citrix components and services, like the Synchronization and Broker Services. These modules contain trace-messages, which when read will tell us their current status, this information is what gets logged as part of the actual CDF trace. These statuses could be telling us that everything is fine, for example or they can produce an error message of some sort pointing us in the right direction.
Takeaways:
- The Local Host Cache ensures that connection Site-wide brokering operations will be able to continue (new and existing connections/sessions) even when the connection between your Delivery Controller (s) and the Central Site Database is down or when your database fails altogether.
- It is used for on-premises as well as Citrix Cloud (cloud connector) environments.
- The Principle Broker Service is part of, or another name for the Broker Service when LHC is involved, which also houses the XML Service and the STA.
- The Config Synchronizer Service (CSS) takes care of all synchronisation operations.
- The High Availability Service/Secondary Broker Service will take over (from the Principal Broker Service) once the LHC becomes active.
- All information is stored in, and synchronised to a Microsoft SQL Server Express (LocalDB) database on the same Delivery Controller.
- Once the Secondary Brokering Service takes over, all VDA’s will re-register themselves with the Secondary Brokering Service.
- Delivery Controllers are listed based on their FQDN’s, which will be used during an election.
- Make sure to configure your controllers with some additional memory, disk space and CPU power.
- This release of the LHC can successfully manage and support up to 5000 VDA’s.






8 responses to “The long awaited… XenApp and XenDesktop 7.12 Local Host Cache”
[…] Read the entire article here, The long awaited… XenApp and XenDesktop 7.12 Local Host Cache […]
[…] So with XenDesktop 7.12 released today I finally got a bit more information on what’s available in the new release. One of the features which was announced was Local Host Cache support is finally back, before I got the time to dig into the material Bas Van Kam did a great blog post on it here –> https://www.basvankaam.com/2016/12/05/the-long-awaited-xenapp-and-xendesktop-7-12-local-host-cache/ […]
Hi Bas,
Thanks for the great article.
Do you know if Citrix is going to add LHC feature for Pooled VDIs in upcoming releases? Is this something in pipeline?
Thanks for reading!
Thank you Bas,
Well articulated and highly informative post on long awaited local host cavhe feature by Citrix in XenApp FMA.
Kind regards,
Stefanos Evangelou
Thanks Stefanos, happy to help.
Nice blogs explaining in details compared to E-Docs.
I have some concerns.
Principle broker service, CCS, Secondary Broker service, Local BD is on all DDC. LHC also will be on all DDCs? How can we check LHC (like XA 6.5, there was a file).
In Normal cases, Sessions will be load balanced among multiple DDCs; CSS will query Principle Broker Service to get changes in every 2 min and Will re-create LHC DB if got positive answer ( changes found). Question is :Principle Broker Service on each DDC will contact to Site DB to get changes (Changes might have been done on other domain controller)? How frequent? Won’t it increase Load on DB?
Secondary Broker Service will also get a list of other Secondary Broker service in Zone (Secondary broker service on other DDC). There will be an election process to elect one working Secondary broker service among these all. In case of failure, Sessions will be served by only this main secondary service hence no session load balancing. All VDAs will be re-registered. Question is : Will it not impact performance of service as all VDA needs to be registered with one Service at the same time.
Thanks in Advance
Vipin Tyagi
Hi Bas!
Thanks again for excellent article and great portion of knowledge :) I have a question regarding the LHC and zones. You wrote that:
“Communication between the various High Availability Services/Secondary Broker Services takes place over a separate channel based on a alphabetical list containing the FQDN’s of the machines they (the services) currently run.”
1. Do you mean that HA Service communicates with all other HA Services in Site? Or just within the zone?
2. What this “separate channel” is?
3. How does it relate to “Controllers in the primary zone are assumed to have good connectivity to the Site database and have some connectivity to all satellite zones. But elements in each satellite zone are not assumed to have connectivity to elements in other satellite zones.” (http://docs.citrix.com/content/dam/docs/en-us/categories/advanced-concepts/downloads/zones-deep-dive.docx)?
Thanks again,
Marcin